Material suplementario · Anexo CCódigo abierto · R & Excel
Galería de scripts
Fragmentos listos para adaptar, cada uno con un ejemplo visual del resultado: visualización, clasificación, supervivencia, meta-análisis, análisis multivariado y utilidades de manejo de datos. Todos probados en proyectos reales de investigación y consultoría.
«El código de este estudio se encuentra disponible… aquí mismo, sin tener que escribirle al autor.»
Declaración de disponibilidad
C.1Visualización
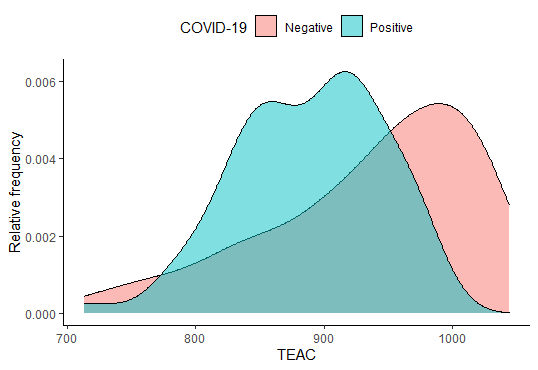
Función de densidad por grupos
Densidades superpuestas con transparencia para comparar la distribución de una variable continua entre grupos.
ggplot2
Figura 1. Densidades por grupo con relleno translúcido. Fuente: elaboración propia (datos simulados).Ver script+
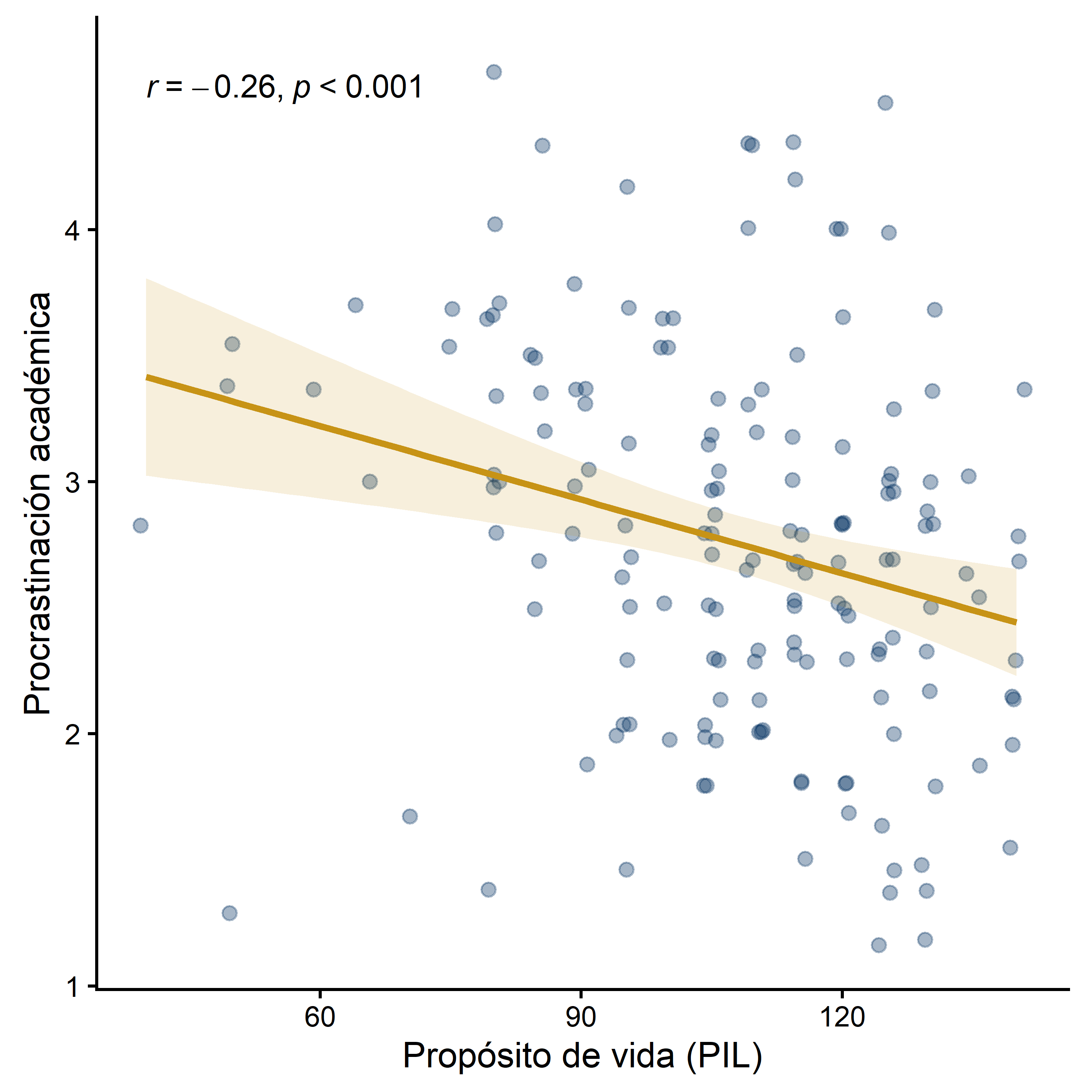
Puntos con jitter y transparencia, recta de mínimos cuadrados con banda de confianza, y el coeficiente de Spearman anotado en el gráfico. Incluye cómo combinar varios paneles con ggarrange.
tidyverse · ggpubr
Figura 2. Dispersión con jitter, recta de regresión y r de Spearman. Fuente: elaboración propia (datos simulados).Ver script+
library(tidyverse)
library(ggpubr)
# Quitar notación científica (si es necesario)
options(scipen = 999)
fig1 <- ggplot(datos, aes(x = VICTIM.MEAN, y = DTM)) +
geom_point(position = position_jitter(width = 0.5, height = 0.5),
alpha = .3) +
geom_smooth(method = lm, color = "black") +
theme_classic() +
labs(x = "Bullying", y = "TMD") +
stat_cor(method = "spearman",
r.digits = 2, p.accuracy = .001,
alternative = "greater", cor.coef.name = "r")
fig1
# Exportar varias figuras en un solo lienzo
png(file = "Scatter.png", width = 18, height = 6, units = "cm", res = 600)
ggarrange(fig1, fig2, fig3,
labels = c("A", "B", "C"),
ncol = 3, nrow = 1)
dev.off()
C.3Visualización
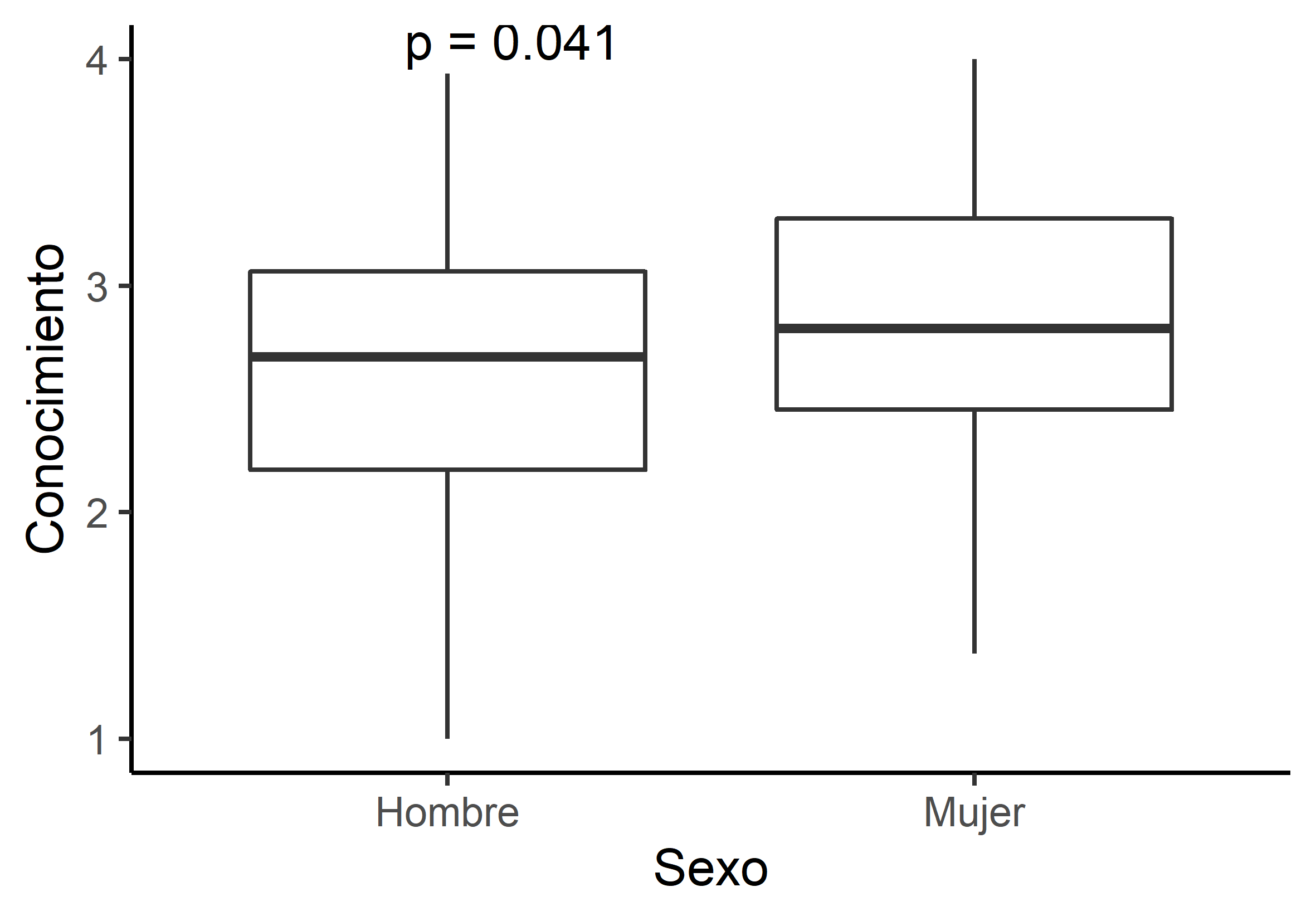
Diagrama de caja con prueba de comparación
Caja y bigotes por grupo con el valor p de la comparación de medias anotado directamente en el gráfico, listo para exportar en alta resolución.
tidyverse · ggpubr
Figura 3. Comparación entre grupos con valor p anotado. Fuente: elaboración propia (datos simulados).Ver script+
library(tidyverse)
library(ggpubr)
# Poner etiquetas a los códigos numéricos
datos$Sexo <- factor(datos$Sexo, levels = c("1", "2"),
labels = c("Hombre", "Mujer"))
plot1 <- ggplot(datos, aes(x = Sexo, y = MedCon)) +
geom_boxplot() +
theme_classic() +
stat_compare_means(aes(label = sprintf("p = %5.3f",
as.numeric(..p.format..)))) +
labs(x = "Sexo", y = "Conocimiento")
# Exportar en alta resolución
png(file = "Grafica1.png", width = 10, height = 7, units = "cm", res = 600)
plot1
dev.off()
C.4Visualización
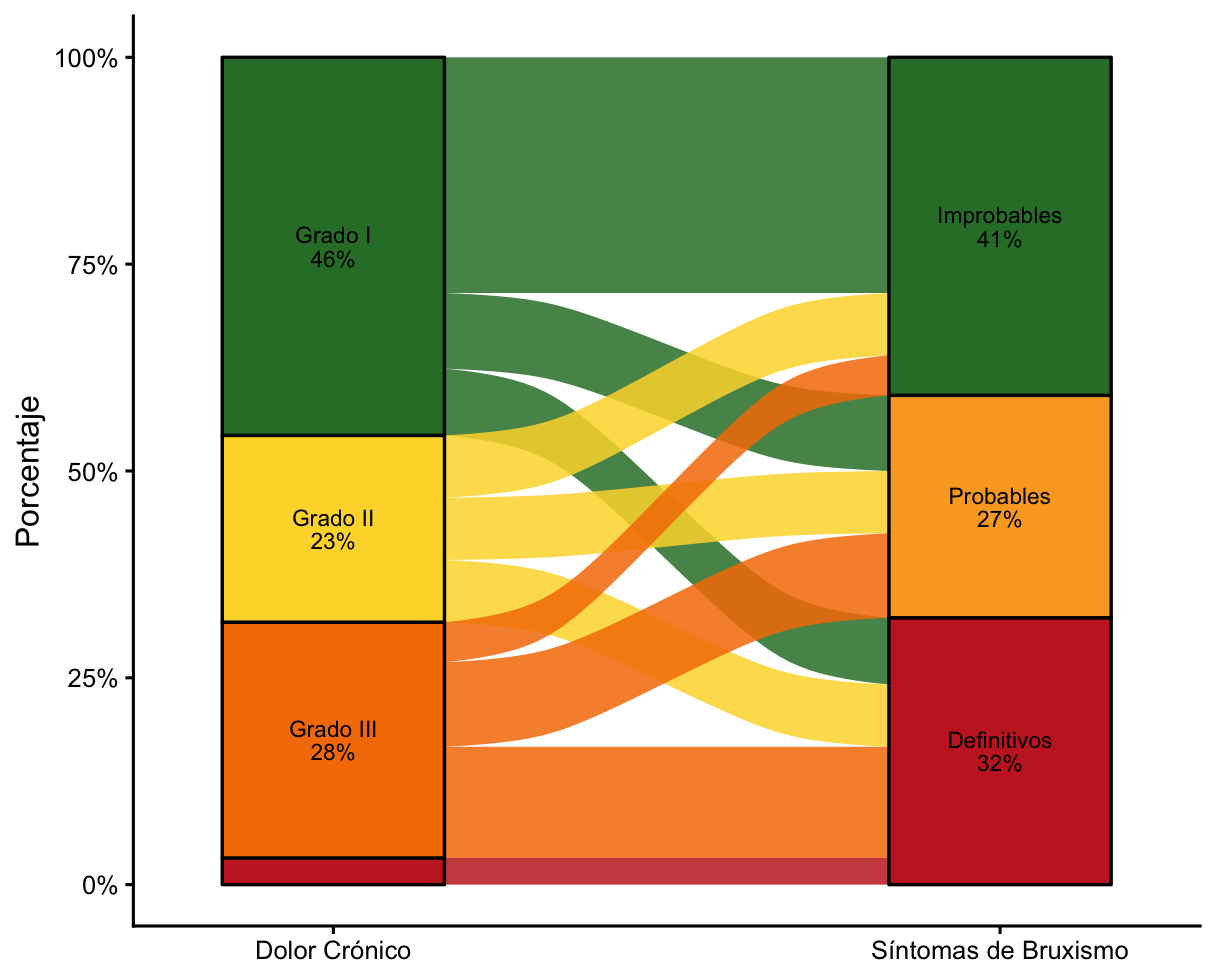
Diagrama aluvial (alluvial plot)
Flujos entre dos variables categóricas — por ejemplo, de grados de dolor crónico a clasificación de bruxismo — con paleta tipo semáforo y etiquetas con porcentajes.
tidyverse · ggalluvial · scales
Figura 4. Flujos entre categorías con paleta semáforo. Fuente: elaboración propia (datos simulados).Ver script+
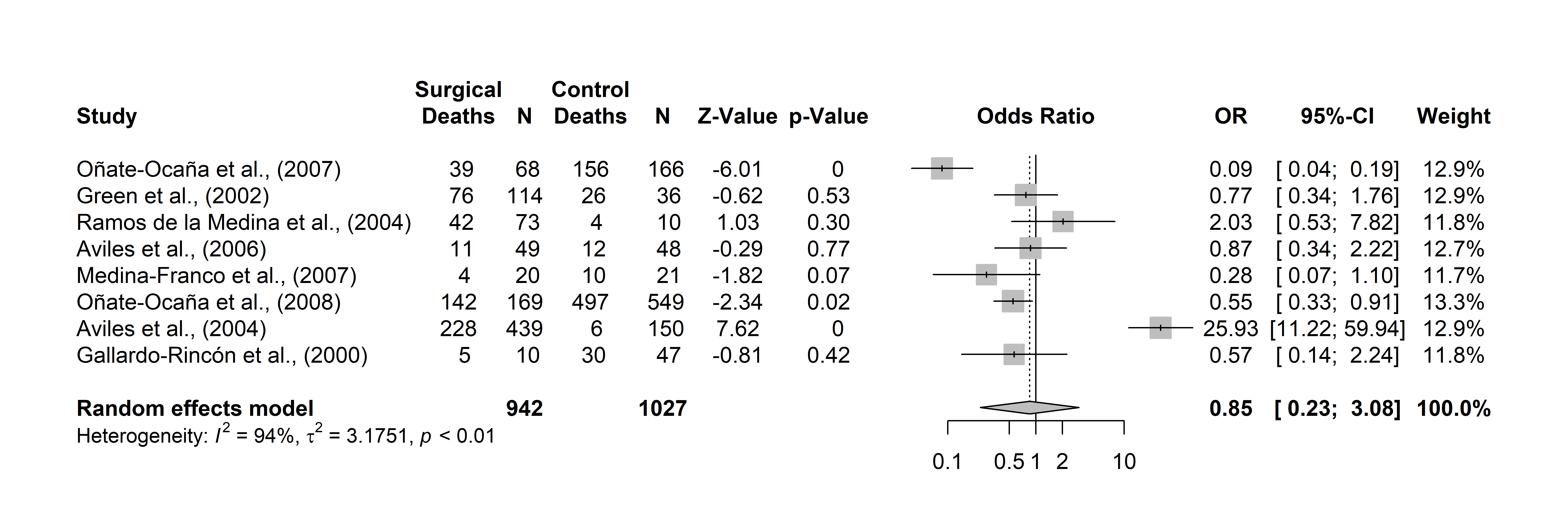
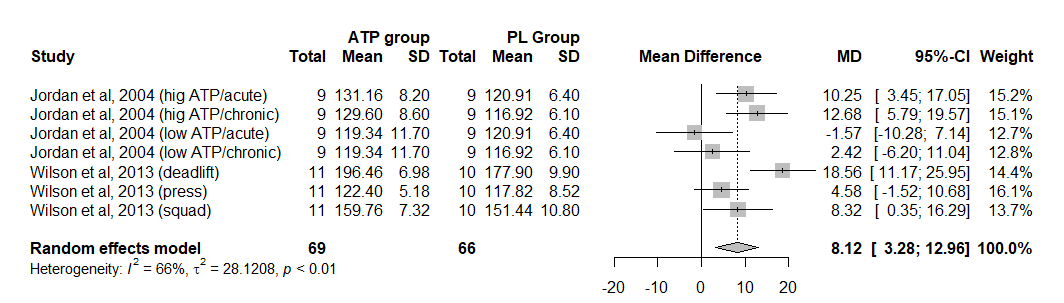
Meta-análisis de eventos binarios (OR / RR) con forest plot
Modelos de odds ratio y risk ratio con el paquete meta, forest plot con columnas personalizadas, prueba de Egger y funnel plot para riesgo de sesgo.
meta · metafor
Figura 7. Forest plot de odds ratios con diamante de efecto global. Fuente: elaboración propia (datos simulados).Ver script+
library(meta)
library(metafor)
# Base: eventos y N de experimental, eventos y N de control
datos_meta <- read.csv("meta_analisis.csv")
# Modelos
ModelOR <- metabin(ne.death, ne, nc.death, nc, Autor,
data = datos_meta, sm = "OR")
ModelRR <- metabin(ne.death, ne, nc.death, nc, Autor,
data = datos_meta, sm = "RR")
# Redondear decimales si es necesario
ModelOR$zval <- round(ModelOR$zval, digits = 3)
ModelOR$pval <- round(ModelOR$pval, digits = 3)
# Forest plot (colocar el modelo a graficar: OR o RR)
forest(ModelOR, comb.fixed = FALSE,
lab.e = "Surgical", lab.c = "Control",
leftcols = c("studlab", "event.e", "n.e", "event.c", "n.c",
"zval", "pval"),
just = "center",
leftlabs = c("Study", "Deaths", "N", "Deaths", "N",
"Z-Value", "p-Value"),
overall = TRUE, layout = "meta")
# Riesgo de sesgo: prueba de Egger + funnel plot
metabias(ModelOR, method = "linreg", k.min = 8)
funnel(ModelOR)
# Exportar en alta resolución
png(file = "forest_OR.png", width = 30, height = 10, units = "cm", res = 600)
forest(ModelOR, comb.fixed = FALSE, layout = "meta")
dev.off()
C.8Meta-análisis
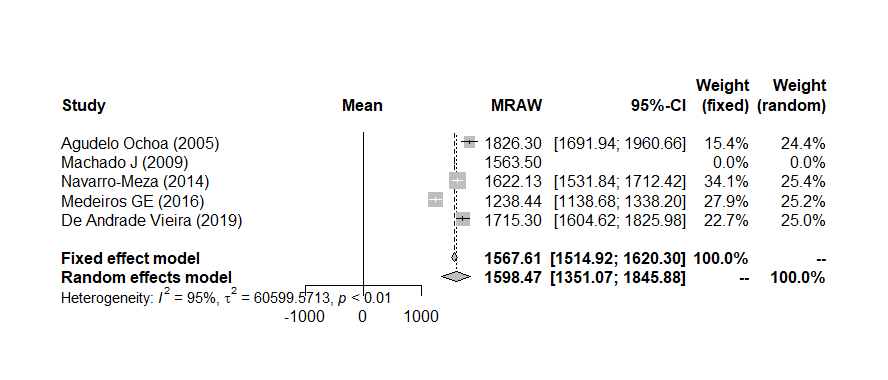
Meta-análisis de promedios (una media por estudio)
Síntesis de medias simples entre estudios con metamean — útil, por ejemplo, para estimar una ingesta calórica promedio combinada.
meta
Figura 8. Forest plot de medias con efecto combinado. Fuente: elaboración propia (datos simulados).Ver script+
library(readxl)
library(meta)
# Base con columnas: Study, n, Kcal (media), sd
datos_meta <- read_excel("ingesta.xlsx")
# Objeto de meta-análisis de medias
meta1 <- metamean(n, Kcal, sd, data = datos_meta, studlab = Study)
meta1
# Forest plot
forest(meta1)
C.9Meta-análisis
Meta-análisis de medias de grupos independientes
Comparación experimental vs. control con metacont (diferencia de medias estandarizada), forest plot con etiquetas de grupos y exportación en alta resolución.
meta
Figura 9. Diferencias de medias estandarizadas entre grupos. Fuente: elaboración propia (datos simulados).Ver script+
library(meta)
# Base con: n, media y sd de cada grupo, por estudio
meta1 <- metacont(n.exp, mean.exp, sd.exp,
n.cont, mean.cont, sd.cont,
studlab = Study, data = datos_meta)
meta1
# Gráfico de bosque
forest(meta1, common = FALSE,
label.e = "Grupo experimental", label.c = "Grupo control",
digits = 2, digits.mean = 2, digits.sd = 2, overall = TRUE)
# Exportar
png(file = "meta_grupos.png", width = 30, height = 10, units = "cm", res = 600)
forest(meta1, common = FALSE,
label.e = "Grupo experimental", label.c = "Grupo control",
digits = 2, digits.mean = 2, digits.sd = 2, overall = TRUE)
dev.off()
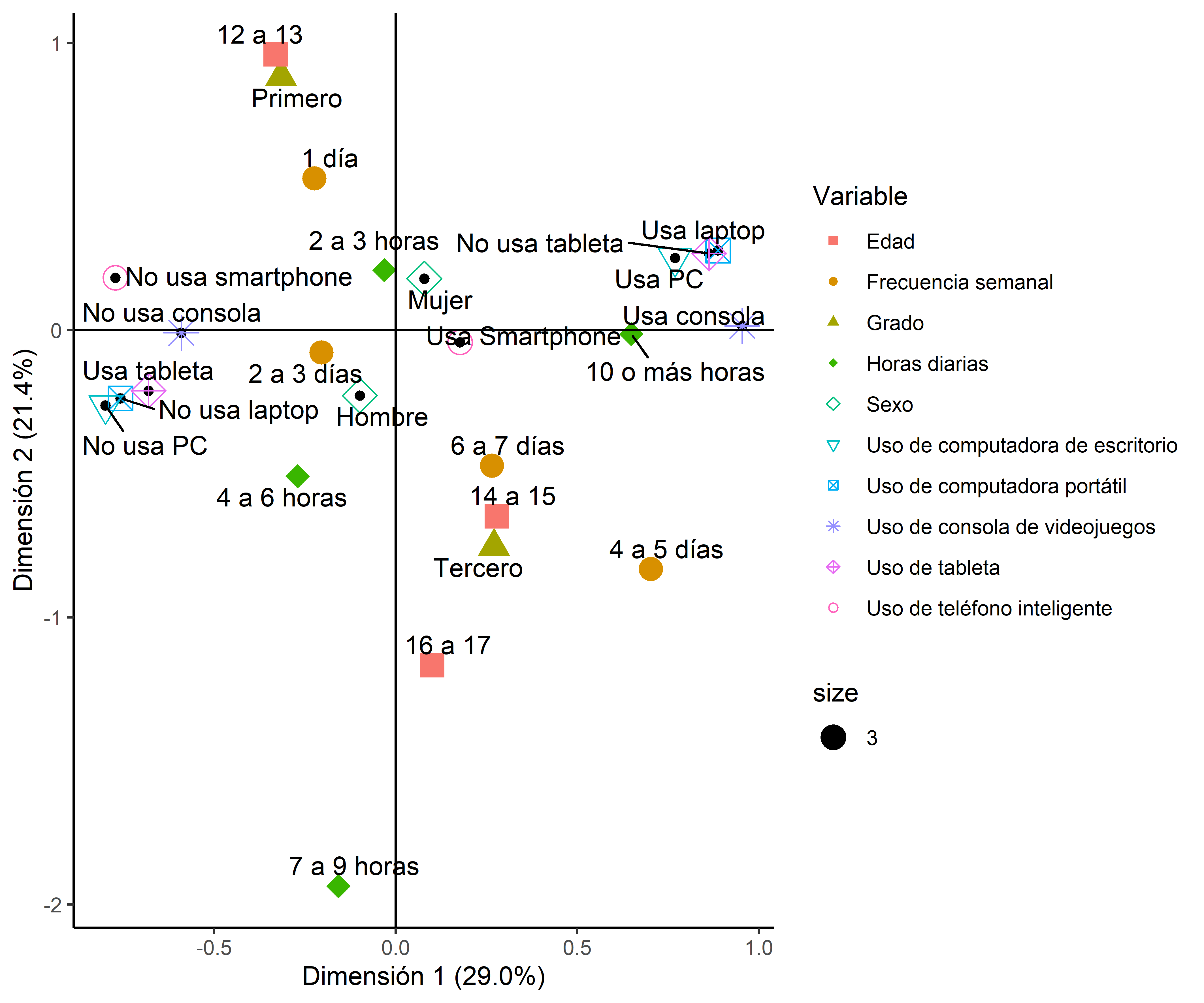
C.10Multivariado
Análisis de Correspondencias Múltiples (biplot)
Mapa de dimensiones con puntos por variable (formas y colores distintos), ejes de referencia en cero, etiquetas sin encimarse con ggrepel, paneles individuales por variable y gráfico de clusters con elipses.
ggplot2 · ggrepel · readxl
Figura 10. Biplot de correspondencias múltiples con formas por variable. Fuente: elaboración propia (datos simulados).Ver script+
library(readxl)
library(ggplot2)
library(ggrepel)
# Base con coordenadas D1, D2, Variable y Categorias
ACM <- read_excel("ACM.xlsx")
# Gráfico conjunto
png(file = "ACM-FINAL.png", width = 18, height = 15, units = "cm", res = 600)
ggplot() +
geom_point(aes(x = D1, y = D2), data = ACM) +
geom_point(aes(x = D1, y = D2, shape = Variable,
colour = Variable, size = 3), data = ACM) +
scale_shape_manual(values = c(15, 16, 17, 18, 5, 6, 7, 8, 9, 1)) +
geom_vline(data = ACM, xintercept = 0.0) +
geom_hline(data = ACM, yintercept = 0.0) +
xlab('Dimensión 1 (36.9%)') + ylab('Dimensión 2 (31.5%)') +
theme_classic() +
geom_text_repel(aes(x = D1, y = D2, label = Categorias),
data = ACM, parse = FALSE)
dev.off()
# Paneles individuales por variable
ggplot() +
geom_point(aes(x = D1, y = D2), data = ACM) +
geom_vline(data = ACM, xintercept = 0.0) +
geom_hline(data = ACM, yintercept = 0.0) +
geom_text_repel(aes(x = D1, y = D2, label = Categorias), data = ACM) +
facet_wrap(~ Variable, ncol = 4)
# Clusters con elipses
ggplot(aes(x = OBSCO1_1, y = OBSCO2_1, color = Clusters), data = ACM) +
geom_point() +
geom_vline(xintercept = 0.0) + geom_hline(yintercept = 0.0) +
stat_ellipse(type = "norm") +
theme_classic()
# Si las variables vienen etiquetadas de SPSS (haven_labelled):
ACM$OBSCO1_1 <- as.numeric(ACM$OBSCO1_1)
ACM$OBSCO2_1 <- as.numeric(ACM$OBSCO2_1)
ACM$Clusters <- as.factor(ACM$Clusters)
C.11Utilidades · Excel
Cambiar multientradas a variables dummy
Cuando una celda guarda varias respuestas juntas ("opción A; opción C…"), esta fórmula crea columnas indicadoras 1/0 buscando cada texto. Funciona mejor y de manera automática dentro de una tabla de Excel.
Excel · SI · ENCONTRAR
Ver fórmula+
=SI(ESNUMERO(ENCONTRAR("TEXTO", CELDA)), "1", "0")
' Ejemplo: columna dummy para la opción "Deporte"
' con las respuestas múltiples en B2:
=SI(ESNUMERO(ENCONTRAR("Deporte", B2)), "1", "0")
C.12Utilidades
Exportar bases de datos a .sav
Convierte bases de Stata (.dta) u otros formatos a SPSS (.sav) conservando las etiquetas de variables y valores — ideal para compartir con colegas que trabajan en SPSS.
haven
Ver script+
library(haven)
# Leer base en formato Stata
datos <- read_dta("base_original.dta")
# Exportar a formato .sav manteniendo etiquetas
write_sav(datos, "base_exportada.sav")
C.13Utilidades
Etiquetar códigos numéricos
El clásico de dos líneas: convierte una variable codificada (1, 2, …) en factor con etiquetas legibles, para que tablas y gráficos muestren nombres en lugar de números.
base R
Ver script+
# Poner nombre a los códigos
datos$Sexo <- factor(datos$Sexo, levels = c("1", "2"),
labels = c("Hombre", "Mujer"))
Nota. Las figuras de esta galería se generaron con datos simulados para ilustrar el tipo de salida de cada script; los resultados con datos reales varían.
C.14
En prensa
El resto de la colección se irá incorporando a la galería.
SEM con mediación: pipeline completo en lavaanSEMEn prensa
Mediación con ecuaciones estructuralesSEMEn prensa
Análisis de Series de TiempoSeries de tiempoEn prensa
Curva de supervivencia de CoxSupervivenciaEn prensa
Funciones de riesgo (hazard)SupervivenciaEn prensa